3.4 KiB
工程数值方法与机器学习
2020/2021 学年
北京航空航天大学微电子学院
授课教师:王鹏教授,邢炜博士
大作业2
问题1
葡萄酒的质量受到了多种理化因素的影响,但最终的质量往往由人们品鉴得到。如何根据能够客观测量的葡萄酒理化指标来鉴定葡萄酒的质量仍然是一个待解决的问题。 在本次作业中,将会提供一份葡萄酒的理化指标与最终质量的数据集,要求在此基础上探究各种理化指标与最终质量的关系。 理化指标共11类,分别为固定酸度,挥发性酸度,柠檬酸,残留糖,氯化物,游离二氧化硫,总二氧化硫,密度,PH值,硫酸盐,酒精。最终质量为10分制得分。 提供给同学们进行训练的数据集为CSV格式文件,共1600条数据。在训练时使用前90%的数据集,并使用后10%的数据集进行测试,基于理化指标对最终质量进行预测,并基于预测结果计算RMSE误差和R2得分(又叫R方,是最常用于评价回归模型优劣程度的指标)
目标1:
使用线性回归完成预测,建立对数据和模型的初步理解。
- 不使用feature mapping(特征映射)完成测试。是否所有理化指标对预测结果都有同等的贡献?哪一些理化指标对结果的权重更大?你是如何得到你的结论的?作图表说明(Tips:使用柱状图对比权重)。
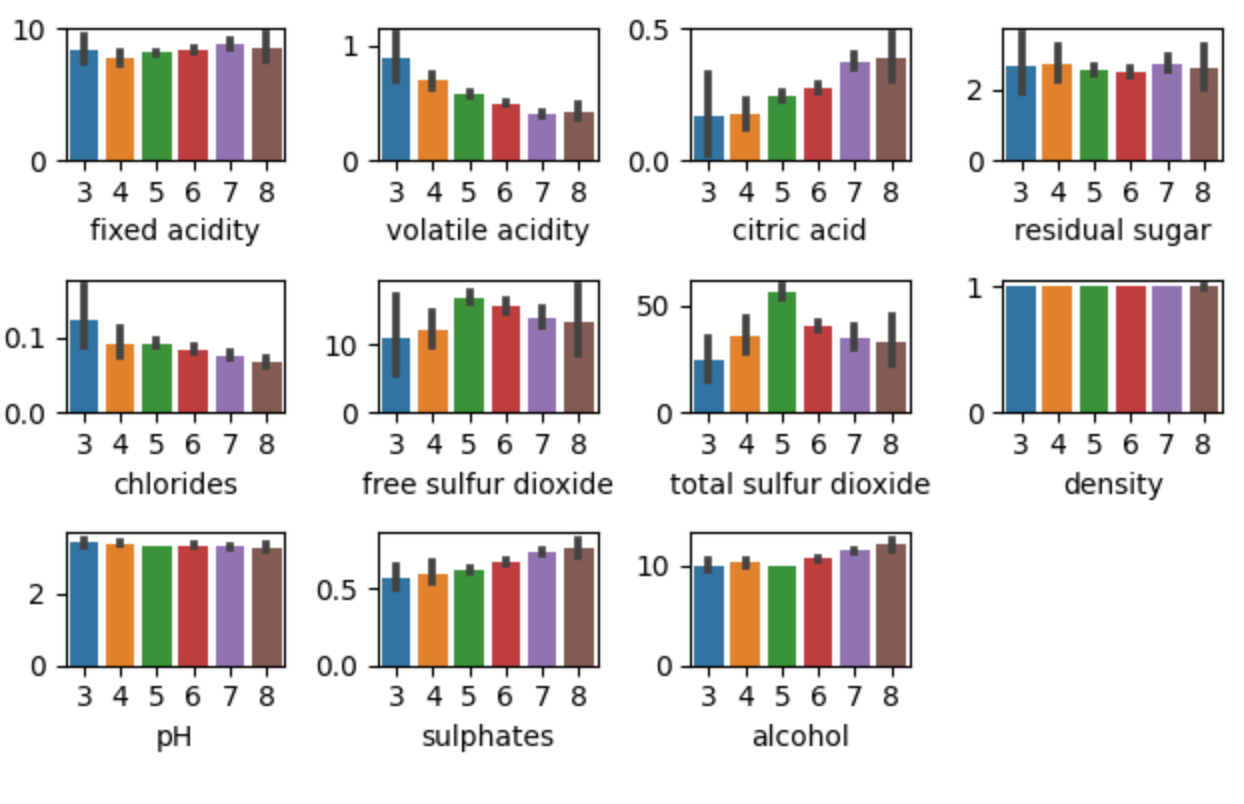
-
引入特征映射,提升模型效果。确定那些对预测结果有用的特征。作图表说明。
-
特征映射的引入可能会造成过拟合,你是如何防止过拟合的?
-
对比1,2,3对应的最佳模型,对比在不同训练数据量的时候,他们之间的RMSE和R2并总结。
目标2:
使用神经网络进行回归预测
使用共11个理化指标作为模型输入,经过大量调试(不同的网络结构,不同的深度,宽度,激活函数,初始化策略,优化函数)确定出最好的网络结构和策略。说明为什么你选择了该模型结构和策略。(你对比了哪些其他的结构?你觉得为什么该模型的效果比较好?如何防止你的选择基准只是一个巧合?)用图表总结你的搜索结果,列出每个模型(或者经过挑选的有代表性的模型)的RMSE,R2和模型训练时间。
-
进一步精调模型,提升模型效果并减少过拟合(例如:dropout,early stopping,bagging,交叉验证,L2/L1正则化等等)。用图表总结你使用的精调方法的带来的效果提升。
-
基于目标1选择出来的最佳特征,重复1,2并作出相应图表。
目标3:
对比目标1和目标2 里面表现最好的模型
- 选择目标1,目标2 里面选得的最优秀的模型,对比他们在不同训练数据下的表现并总结,作图。
作业提交有效时间是今天到12月29日(三周后)之前的任意时间。 提交作业请将代码和报告打包,以“学号-姓名-UQ”命名提交至链接 [http://www.xzc.cn/YvcM5sqqVm]
# 运行
cd numerical_analysis/8
python main.py
随机森林
R2: 0.475379
accuracy: 0.687500
线性回归
R2: 0.297383
accuracy: 0.587500
支持向量机
R2: 0.250542
accuracy: 0.681250
随机梯度下降
R2: -0.124188
accuracy: 0.475000
多层感知器
R2: 0.288015
accuracy: 0.637500